Abstract
3D-aware generative adversarial networks (GANs) synthesize high-fidelity and multi-view-consistent facial images using only collections of single-view 2D imagery. Towards fine-grained control over facial attributes, recent efforts incorporate 3D Morphable Face Model (3DMM) to describe deformation in generative radiance fields either explicitly or implicitly. Explicit methods provide fine-grained expression control but cannot handle topological changes caused by hair and accessories, while implicit ones can model varied topologies but have limited generalization caused by the unconstrained deformation fields. We propose a novel 3D GAN framework for unsupervised learning of generative, high-quality and 3D-consistent facial avatars from unstructured 2D images. To achieve both deformation accuracy and topological flexibility, we propose a 3D representation called Generative Texture-Rasterized Tri-planes. The proposed representation learns Generative Neural Textures on top of parametric mesh templates and then projects them into three orthogonal-viewed feature planes through rasterization, forming a tri-plane feature representation for volume rendering. In this way, we combine both fine-grained expression control of mesh-guided explicit deformation and the flexibility of implicit volumetric representation. We further propose specific modules for modeling mouth interior which is not taken into account by 3DMM. Our method demonstrates state-of-the-art 3D-aware synthesis quality and animation ability through extensive experiments. Furthermore, serving as 3D prior, our animatable 3D representation boosts multiple applications including one-shot facial avatars and 3D-aware stylization.
Video
Framework Overview
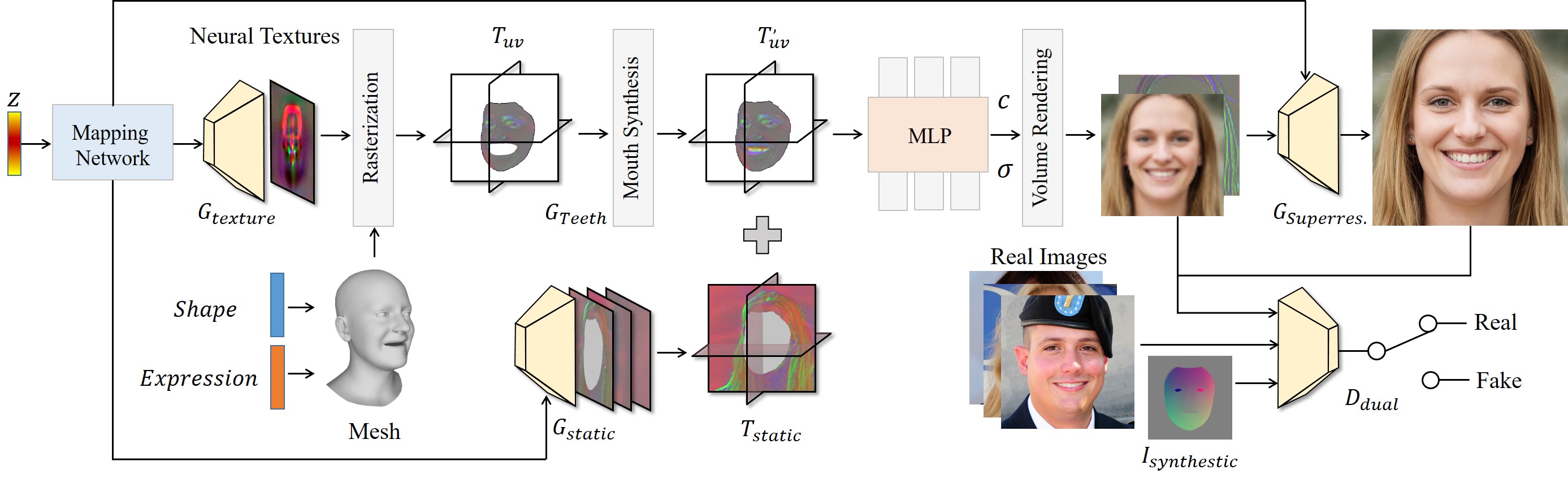
We propose a novel 3D GAN framework for unsupervised learning of generative, high-quality and 3D-consistent facial avatars from unstructured 2D images. To achieve both deformation accuracy and topological flexibility, we present a 3D representation called Generative Texture-Rasterized Tri-planes. The proposed representation learns Generative Neural Textures on top of parametric mesh templates and then projects them into three orthogonal-viewed feature planes through rasterization, forming a tri-plane feature representation for volume rendering. In this way, we combine both fine-grained expression control of mesh-guided explicit deformation and the flexibility of implicit volumetric representation. We further propose specific modules for modeling mouth interior which is not taken into account by 3DMM.
Geometry Visualization
Next3D generates high-quality dynamic shapes with topological changes. As can be seen, we model detailed dynamic shapes of eyelids and lips, while keeping glasses unchanged.
One-Shot Facial Avatars
The learned generative animatbale 3D representation with expressive latent space can serve as a strong 3D prior for high-fidelity single-view 3D reconstruction and animation. Note that we can generate natural and consistent animations without video data training.
3D-Aware Stylization
we incorporate 2D CLIP-guided style tranfer methods with our animatable 3D representation for 3D-aware portrait stylization.
BibTeX
@inproceedings{sun2023next3d,
author = {Sun, Jingxiang and Wang, Xuan and Wang, Lizhen and Li, Xiaoyu and Zhang, Yong and Zhang, Hongwen and Liu, Yebin},
title = {Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars},
booktitle = {CVPR},
year = {2023}
}