Overview
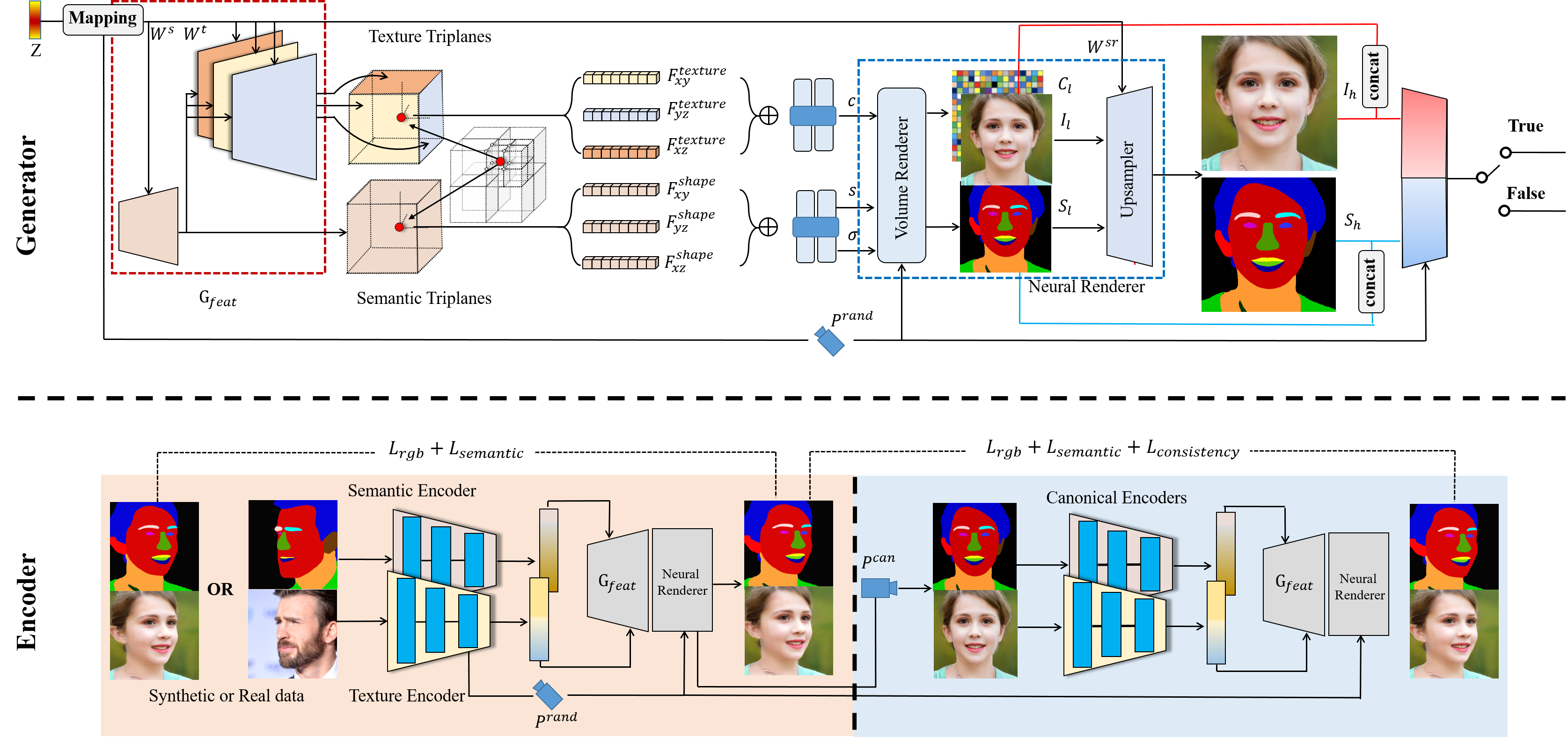
Pipeline of our 3D generator and encoders. The 3D generator (upper) consists of several parts. First, a StyleGAN feature generator Gfeat constructs the spatially aligned 3D volumes of semantic and texture in an efficient tri-plane representation. To decouple different facial attributes, shape and texture codes are injected separately into both the shallow and the deep layers of Gfeat. Moreover, the deep layers are designed to three parallel branch corresponding to each feature plane to reduce the entanglement among them. Given the generated 3D volumes, RGB images and semantic masks can be rendered jointly via the volume rendering and a 2D CNN-based up-sampler. Encoders (lower) embeds the portrait images and corresponding semantic masks into the texture and semantic latent codes by two independent proposed encoders. With a predicted camera pose, Then the fixed generator reconstructs the portrait under the predicted camera pose. In order to eliminate pose effect, we jointly train a canonical editor which takes as input the portrait images and semantic masks under the canonical view, with the consistency enforcement.